
今年高考,我让12个顶级AI一起考了语文和数学,结果有点意外。
一年一度的高考季又到了。
从上上周开始,就有很多朋友来问我,今年高考还测不测大模型考试了。
测,肯定测。
但是肯定要跟去年要有一些区别对吧,去年我只测了部分的数学题,今年要是还这么玩,那就太无聊了。
所以,我想了想,今年不如整个大一点的活,让所有的顶级AI一起,来全面的考一下语文和数学,这两个,全都考。
在所有AI都在发力代码和Agent能力的情况下,究竟谁的语文能力最高,我还是非常好奇的。
这次的参赛模型呢,基本市面上主流的大模型我也都拉来了,基本都是大家的旗舰模型。
国外基本就是大家熟悉的御三家,Claude Opus 4.8、GPT-5.5、Gemini 3.1 Pro。
国内这边,我也尽量选了各家现在最能打的。
千问3.7 max、文心Ernie 5.1、星火Spark X2、智谱GLM5.1、Kimi k2.6、MiniMax M3、DeepSeek V4 Pro、小米MiMo v2.5 Pro、混元3这些都有。
让这些大模型,一起做了这两套卷子。
而我肯定没有对语文和数学高考题目阅卷的能力,所以这次,我想了想,找身边的朋友们化了下缘,终于,也邀请到了4位有过类似阅卷经历的高中老师们,来跟我们一起整这个活。
因为语文会稍微主观一点点,并且我们也不像真的高考一样有一些打分细则,所以我们邀请了3位语文老师来共同阅卷,让他们充分发挥,最后取平均分,这样会公平一点,所以最终是3位语文老师和1位数学老师。
但是真的非常非常感谢几位老师,陪我们一直干到了凌晨,每个人几乎都认真批改了十二份的卷子。。。真的,无以为报。。。
而卷子的挑选上,虽然也都是选用的全国一卷,这次会稍微有点特殊。
因为语文这次比较可惜,等到晚上8点也没有等到完整版的卷子,所以只能最终使用中国考试官方发布的部分试题和参考答案上进行测试,满分大概是100分,最终分数会基于比例,再换算至150分。

数学则是完整的真题试卷,就比较简单了。

然后呢,为了保证这次AI高考的公平性,我们还是下了不少功夫做平衡的,限制了不少规则:
1. 使用API调用各个模型,都开thinking,不限制最长的token数,所有的工具调用都强行禁止,像什么代码推理、网页搜索什么的都关掉了。
2. 除了讯飞星火、百度,其他10家统一走OpenRouter调用,这样可以保证最公平公正。
3. 模型的输入,语文和数学都采取了通过LaTeX格式纯文本输入的方式。
数学本来我们打算是分成多模态和纯文本赛道的,但是真题一出来之后,发现只有一道题,也就是立体几何那道题带图形。但题干其实就完全包含了这个图形的所有信息,没有必要,所以就改成了全部都通过LaTeX格式输入。

虽然PDF转LaTeX格式这一步是AI做的,但是让它转了之后,我也同样写了一个LaTeX编译器的脚本,它会在左边放上原本的题目,右边是LaTeX数据编译后的最终题目,方便我和老师们进行核对,在准确性上,我们还是花了一些力气的。

然后我们也开发了一个自己的考试脚本,我们只需要把题目丢进去,脚本就会自动调 API,自动让模型作答,自动把客观题判掉,主观题再送到我搭的在线阅卷平台里,让真人老师盲评。
考试的Prompt按照下面的设置给模型。
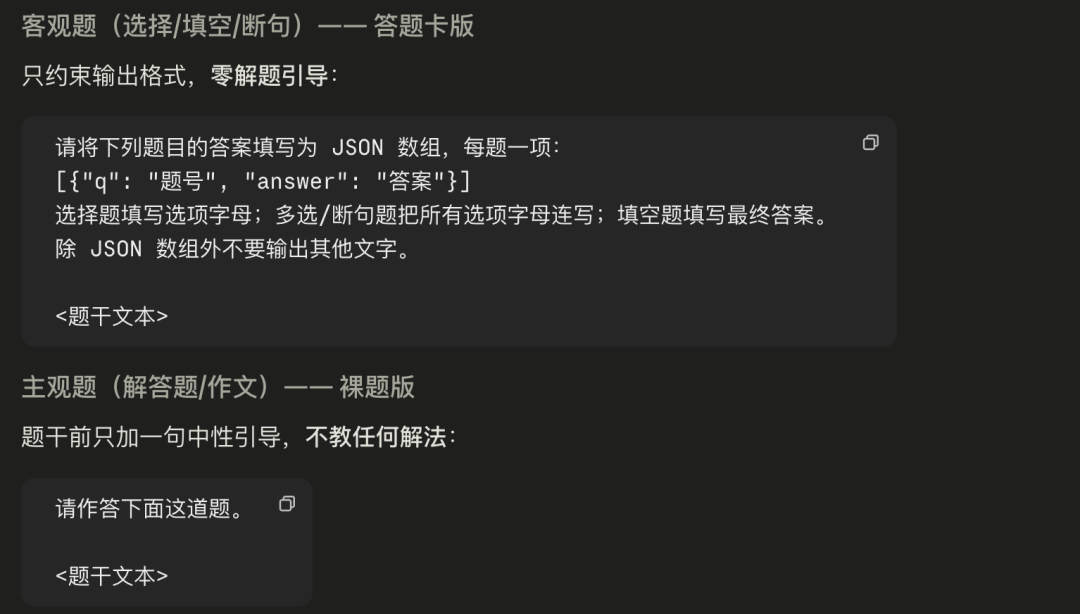
客观题只是单纯限制它的格式输出,方便我的脚本对客观题进行打分,不做任何的引导。
主观题就直接把裸题给模型丢过去让他作答。
以及在数学的填空题上面,也是让它根据数值打分,不是根据格式打分。因为填空题容易出现,在分数或者说有根号的情况下,会有不同的写法,同一个数值会有不同的写法。所以这次在脚本中也是有格外注意这一点。
反正作答上我们尽量确保要公平、公平再公平,客观、客观再客观。
最后,模型输出的所有的结果,我们又开发了一个阅卷网站,供我们的4位老师们进行阅卷和评分。
老师使用自己的名字,登进去之后,看到的每份卷子上面只有一个代号。卷ABCD巴拉巴拉。
这样的话,老师并不知道这道卷子是哪一个模型做的答,也会避免一些前置的刻板印象带来一些阅卷上的影响。
老师可以随意选择一套卷子开始阅卷,然后里面的打分界面是这样的。
直接在里面逐题批改。

还可以写上自己的评语。
真的,老师们特别辛苦,因为语文的卷子迟迟不出最终版,所以我们最后只能用部分版来考试,几位老师都生生的阅卷到晚上11点以后了。

向老师们致敬。
最后,在经历了将近12个小时的奋战之后,我们的12位大模型的考试分数,终于出炉了。
他们,是这样的。
这里我提前叠个甲,这个分数和排名,只是我们基于自己的体系做题出来并且由老师们主观评选出来的,而且只跟语文和数学做题有关,跟大家现在讨论的代码和Agnet能力无关,且可能会展示部分的人类偏好,排名与分数仅供娱乐参考,不代表任何指向。

这里面有几个让我挺意外的地方。
先看总分,第一名MiMo v2.5 Pro,256.3分。第二名Kimi k2.6,256.29分。
差了0.01分。
MiMo比Kimi语文少了1分,Kimi数学比MiMo多了1分。。。
要知道我们测评的语文卷子只有一道客观选择题,其他全是主观题,再加上有作文的存在,换算到实际评分上,可能就是某位语文老师在某道主观题上多给了1分的区别。
往下看从第三名到第九名,Claude Opus 4.8,一直到GLM 5.1和Gemini 3.1 Pro并列的252.78,7个模型之间的差距仅仅在2分。
可以说,至少在这两套高考卷子上的表现,前面这9个顶级的AI大模型模型几乎真的都拉不开差距了,分差极小。
看完了总分,再来看看单科的成绩。
你会发现,我们的语文状元在3位老师盲测中,由GLM5.1和Gemini 3.1 Pro共同摘夺桂冠,但是在数学上又有点偏科,而且几乎都是兄弟肩并肩,我的脑子里已经出现了中学班上某一个同学的样子了。。。
反过来的例子也有,DeepSeek V4 Pro,和MiMo、ERNIE 5.1三家并列数学最高分,但语文又奇低。。。
坦率的讲,这其实不太符合我对DeepSeek强世界知识的印象。
我把语文的评分单独拎出来看了下,这里注意一下,因为语文真题目前全部的还没出来,所以现在用的是部分的题集合成的101分版本,最后折算成150分制的,所以下面你看到的总分其实都是101分制的。
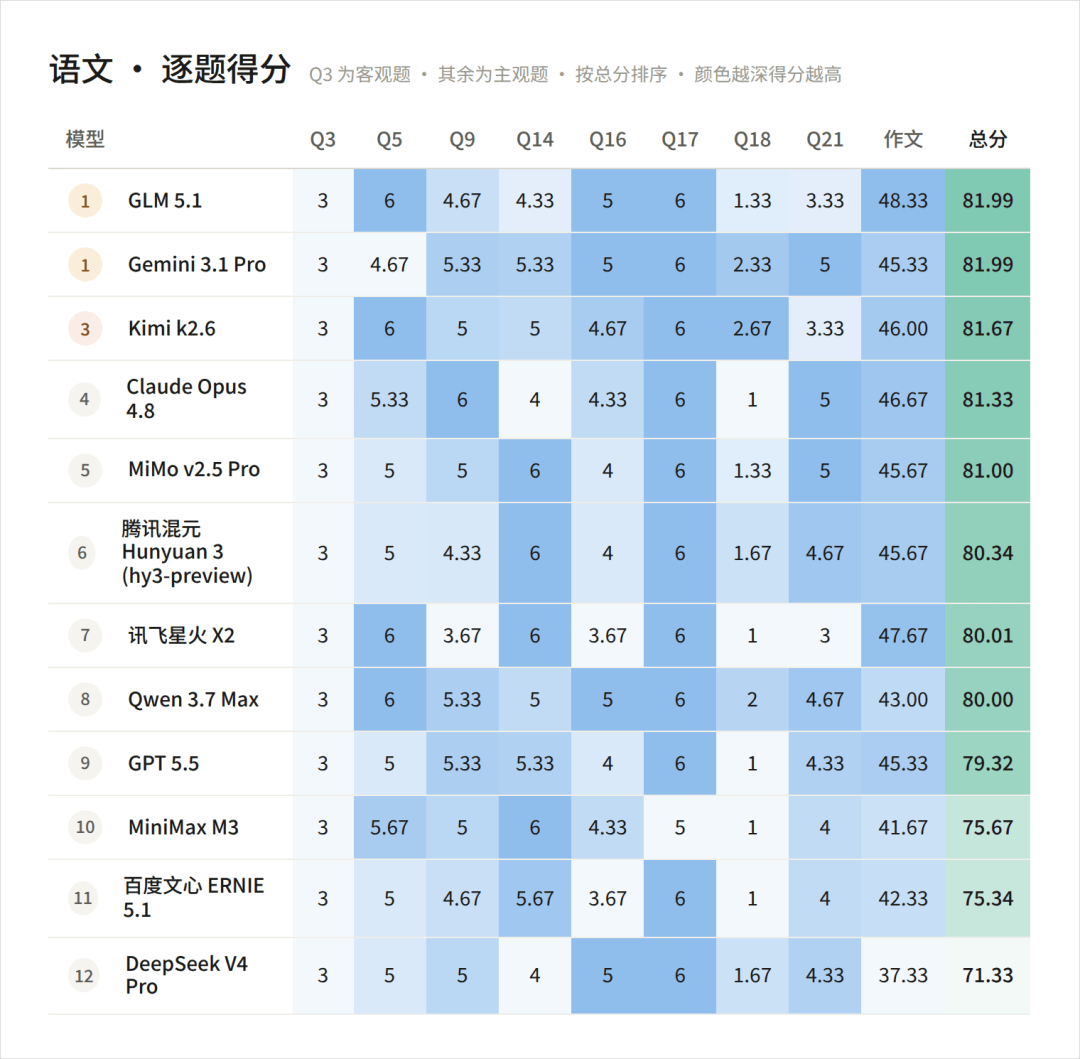
发现DeepSeek的作文,属于拉完了。

最后一位老师手比较松,虽然打出的分数是49分,但是在他过去的打分中,其实也不算高了。
他们的评语其实也都非常的有意思。
所以他们一改完卷,我也去认真看了看他们所有的评语。
其实三位老师从给分上看,是能看出来他们有各自的偏好,但是在他们的评语有一个共同点。
他们很在意高考作文的可评分结构。
评语里会高频出现文体不清,文章结构不够清晰,观点不够清晰明确,论证不充分,时代关联不足等等评语。
比如这一篇所有模型中得分最高的,由GLM 5.1写的作文,就有两位老师都提出了文章结构不够清晰的毛病。
作文原文我也放在这里了,大家可以在评论区评一评。

语文大概就是这样,我们再看看数学的得分明细。

你会发现几乎所有的模型,其实没啥大的分差。
我也从数学老师那里得到了非常积极的反馈,刚改完前面几个大题,他就在很兴奋的跟我说,发现正确率挺高的,基本都是满分。
不过唯一一道让大家全军覆没的,就是填空题的最后一题。
懂的人可以来说一说这是个什么难度,反正我不太懂= =
还有一个有意思的就是,我在让Opus 4.8跑数学最后一道大题的时候,他莫名其妙的卡死了很多很多轮。。。
不太有意思的就是,我忘记它一直在重试,导致我OpenRouter上为数不多的余额全给耗光了。。。
不过最后好歹还是搞出来了。
以上,大概就是这次AI高考的结果,跟我最开始预期的,还真的是有点区别。
我又做了一下各家的位置图,大家可以看看。

真的是情理之中,又是预料之外。
还挺好玩的。
忽然又想起,2023年,我第一次拿高考题去测AI。
当时是让ChatGPT去写高考作文。

那会儿GPT-4还是最能打的,国产模型甚至都还没有几个。
2024年,国产也开始卷起来了,但还是有很多哭笑不得的翻车。去年2025那次测完,有几个模型的数学水平已经够上一本线了。
今年是2026。
四年了。
也算是见证了那好多好多个模型的浮沉。
我们自己也在变,23年的时候,只会写个作文,去年测试,还是人工复制粘贴到十几个大模型的官网里面去测试,不断的roll。
今年,写批量脚本,写LaTeX转译,请高考阅卷老师们助阵,又为他们徒手开发了阅卷网站。
我当然也可以随手测一下整个活,但是想了想,这几年,在这个选题上,我觉得还是要尽可能的保证客观和公平。
因为,这是高考。
这两个字,在中国,承载的东西太多也太厚重了。
做阅卷网站的时候,我一直在纠结用什么主意象,最后选了凤凰花。
六月的凤凰花开得正盛,每年都准时赶在这个节点上,送走一届又一届的人。
最后。
我想用最近一段对我非常有感触的话来结尾,它来自《燕云十六声》最近更新的青州地图的最后的任务,当一众学子即将毕业之时,文津馆文元林险生对大家说:
“你们,自天南地北负笈而来,今日散去,又是去往天南地北,此后山长水远,很多人将不复相见了。
此去,必有风霜凛冽之时,愿诸君,乾坤既大,草木尤青,本心择路,笃志前行。
各位,一路顺风。”